26 Image segmentation and object detection
26.1 Overview
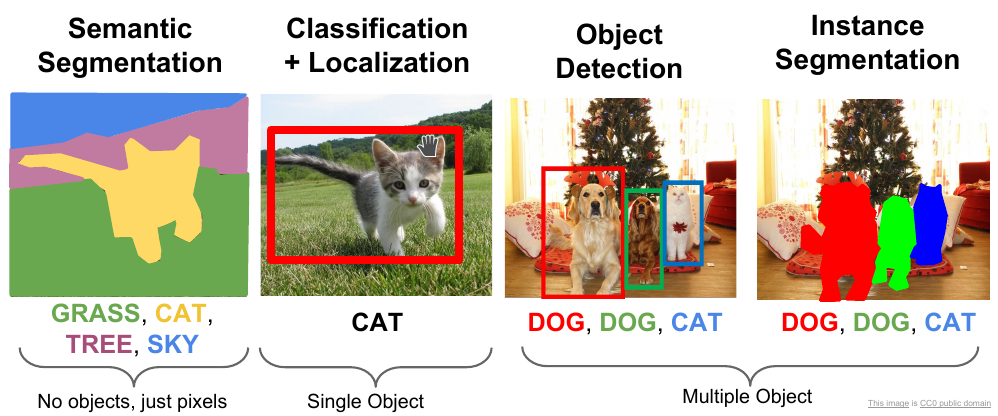
Image segmentation is the process of dividing an image into multiple segments, or regions, each of which corresponds to a distinct object or part of the image. The goal of image segmentation is to simplify the representation of an image into meaningful and easy-to-understand parts, which can then be used for further analysis or manipulation.
There are several techniques for image segmentation, including thresholding, edge detection, region growing, and clustering.
- Thresholding involves dividing the image into two or more parts based on a particular threshold value, such as pixel intensity or colour.
- Edge detection involves identifying the edges of objects in the image based on changes in intensity or colour.
- Region growing involves grouping together pixels that have similar properties, such as intensity or texture.
- Clustering involves grouping pixels based on similarity in features, such as colour, texture, or shape.
Image segmentation has many applications, such as object recognition, image editing, and medical imaging. For example, in object recognition, image segmentation can be used to identify the boundaries of objects in an image and extract features for use in a machine learning model. In image editing, image segmentation can be used to remove or replace specific objects or parts of an image. In medical imaging, image segmentation can be used to identify and segment different tissues or structures in an image, which can be used for diagnosis or treatment planning.
For efficient image segmentation with machine learning, Python with TensorFlow is recommended, and interested readers may find the reference page on Image segmentation with a U-Net-like architecture useful.
Object detection
Object detection based on segmentation is a technique that combines object detection and image segmentation to identify and localise objects in an image or video. This approach involves first segmenting the image to obtain a set of candidate regions that potentially contain objects. Each candidate region is then analysed to determine whether it contains an object, and if so, to classify the object.
There are several methods for object detection based on segmentation, including region-based convolutional neural networks (R-CNN), Mask R-CNN, and instance segmentation.
Region-based convolutional neural networks (R-CNN) first segment the image into regions of interest using a segmentation algorithm such as selective search. These regions are then passed through a convolutional neural network (CNN) to extract features, followed by a classifier to classify the objects contained within the regions.
Object detection based on segmentation has numerous applications in various fields, including robotics, self-driving cars, and medical imaging. For example, in robotics, object detection based on segmentation can be used to identify and locate objects for manipulation or navigation tasks. In self-driving cars, object detection based on segmentation can be used to detect and track other vehicles, pedestrians, and traffic signs. In medical imaging, object detection based on segmentation can be used to detect and locate tumours or other abnormalities in medical scans.
Object detection based on segmentation is a powerful technique that can accurately and efficiently detect and locate objects in images or videos, with numerous applications in various fields.
Performing object detection with region-based convolutional neural networks (R-CNN) in R typically involves using pre-trained models and specialized packages. One popular package for object detection in R that allows it is reticulate, which allows you to interface with Python libraries. Here’s an example of how you can use R to perform object detection using R-CNN:
# Install and load the required packages
install.packages("reticulate")
library(reticulate)
# Load the Python libraries
cv2 <- import("cv2")
numpy <- import("numpy")
tensorflow <- import("tensorflow")
tf <- tensorflow$compat$v1
# Load the pre-trained R-CNN model
rcnn_model <- tf$keras$models$load_model("path/to/rcnn_model.h5")
# Load and preprocess the image
image <- cv2$imread("path/to/image.jpg")
image <- cv2$cvtColor(image, cv2$COLOR_BGR2RGB)
image <- numpy$array(image, dtype="float32")
image <- numpy$expand_dims(image, axis=0)
# Perform object detection
preds <- rcnn_model$predict(image)
boxes <- preds$reshape(-1, 4)
scores <- preds$reshape(-1)
# Set the confidence threshold
confidence_threshold <- 0.5
# Filter the detected objects based on confidence threshold
filtered_boxes <- boxes[scores > confidence_threshold, ]
filtered_scores <- scores[scores > confidence_threshold]
# Display the detected objects
for (i in 1:nrow(filtered_boxes)) {
box <- filtered_boxes[i, ]
cv2$rectangle(image, tuple(box[1:2]), tuple(box[3:4]), (0, 255, 0), 2)
}
# Show the image with detected objects
cv2$imshow("Object Detection", image)
cv2$waitKey(0)
cv2$destroyAllWindows()