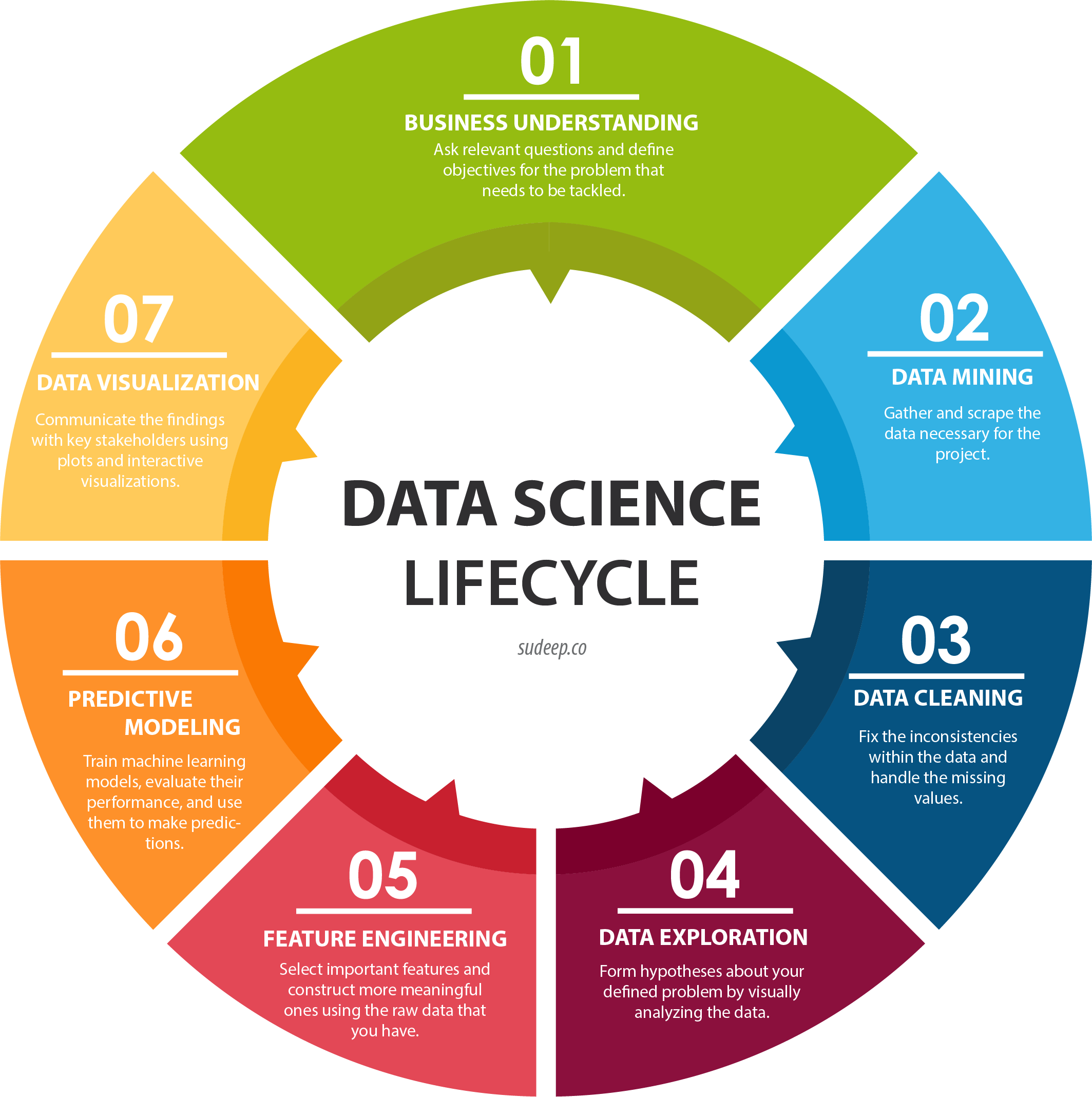
The Data Science Universe
Data science is an exciting discipline that allows you to transform raw data into understanding, insight, and knowledge. Data science is a vast field, and there’s no way you can master it all by reading a single book. This book aims to give you a solid foundation in the most important tools and enough knowledge to find the resources to learn more when necessary. Our model of the steps of a typical data science project looks something like Figure 1.
How this book is organized
Below is a list of items we are going to cover in this book:
Data Science and R
Data Exploration and Visualization
Supervised Learning
Unsupervised Learning
Boosting and Random Forest
Natural Language Processing
Image Processing/Computer Vision
Reinforcement Learning
Big Data & Cloud Computing
Why Learning data science?
As more and more businesses move towards digitalization, there is a growing demand for professionals who can analyze and make sense of the vast amounts of data that are being generated. This has created a significant shortage of skilled Data Scientists, making it a highly sought-after and well-compensated profession.
Another point is that, Data Science is a highly interdisciplinary field that combines knowledge and techniques from statistics, computer science, and domain-specific areas. This means that learning Data Science can enhance your critical thinking skills, improve your ability to solve complex problems, and provide you with a unique set of skills that are highly valued in the job market.
The Role of R
R is a programming language that is widely used in the field of Data Science. Its role in Data Science is multifaceted and can be summarized as follows:
Data Wrangling: R has a powerful set of libraries that allow you to manipulate and transform data, which is a critical step in any Data Science project.
Statistical Analysis: R has a rich set of statistical libraries that allow you to perform a wide range of statistical analyses, including hypothesis testing, regression analysis, and time series analysis.
Data Visualization: R has an extensive set of libraries for creating high-quality data visualizations, such as plots, charts, and graphs, that enable you to communicate insights effectively.
Machine Learning: R has a comprehensive set of libraries for building and deploying machine learning models, such as decision trees, random forests, and neural networks.
Reproducibility: R provides a framework for creating reproducible data analyses, which is essential for collaborating with others and ensuring that your work can be verified and replicated.
Overall, R plays a critical role in the Data Science process by providing a powerful and flexible toolset for manipulating, analyzing, and visualizing data, building and deploying machine learning models, and ensuring reproducibility.